Made by Ziyang CHEN, Rocky, 陈子阳
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
个人笔记,仅供参考 (FOR REFERENCE ONLY)
1. Basic Python syntax
Identifiers
1
2
3
|
a1 = 0 ✅ _a1 = 0 ✅ 1a = 0 ❌
|
多行显示
1
2
3
4
5
6
7
|
total = a + \
b - \
c
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']
|
引号 & 注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
word = 'word'
sentence = "这是一个句子。"
paragraph = """这是一个段落。
包含了多个语句"""
'''
我是多行注释
我是多行注释
'''
"""
我是多行注释
我是多行注释
"""
|
同一行显示多条语句 & 多个变量赋值
1
2
3
4
5
6
7
8
| a, b, c = 1, 2, "john"
print (a,b,c)
print('---------')
print(a)
print(b, end=" ")
print(c, end=" ")
|
1
2
3
4
| 1 2 john
---------
1
2 john
|
六个标准数据类型
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组)
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
1. Numbers(数字)
1
2
3
4
| x = 1; y = 1.5
a, b, c, d = 20, 5.5, True, 4+3j
print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
|
2. String(字符串)
- 字符串截取语法格式:
变量[头下标:尾下标:步长], 从左往右以 0 开始, 从右往左以 -1 开始, 下标可以为空表示取到头或尾
1
2
3
4
5
6
7
8
9
10
11
12
13
| str='123456789'
print(str)
print(str[0:-1])
print(str[0])
print(str[-1])
print(str[2:5])
print(str[2:])
print(str[1:5:2])
print(str * 2)
print(str + '你好')
print('hello\nrunoob')
print(r'hello\nrunoob')
|
1
2
3
4
5
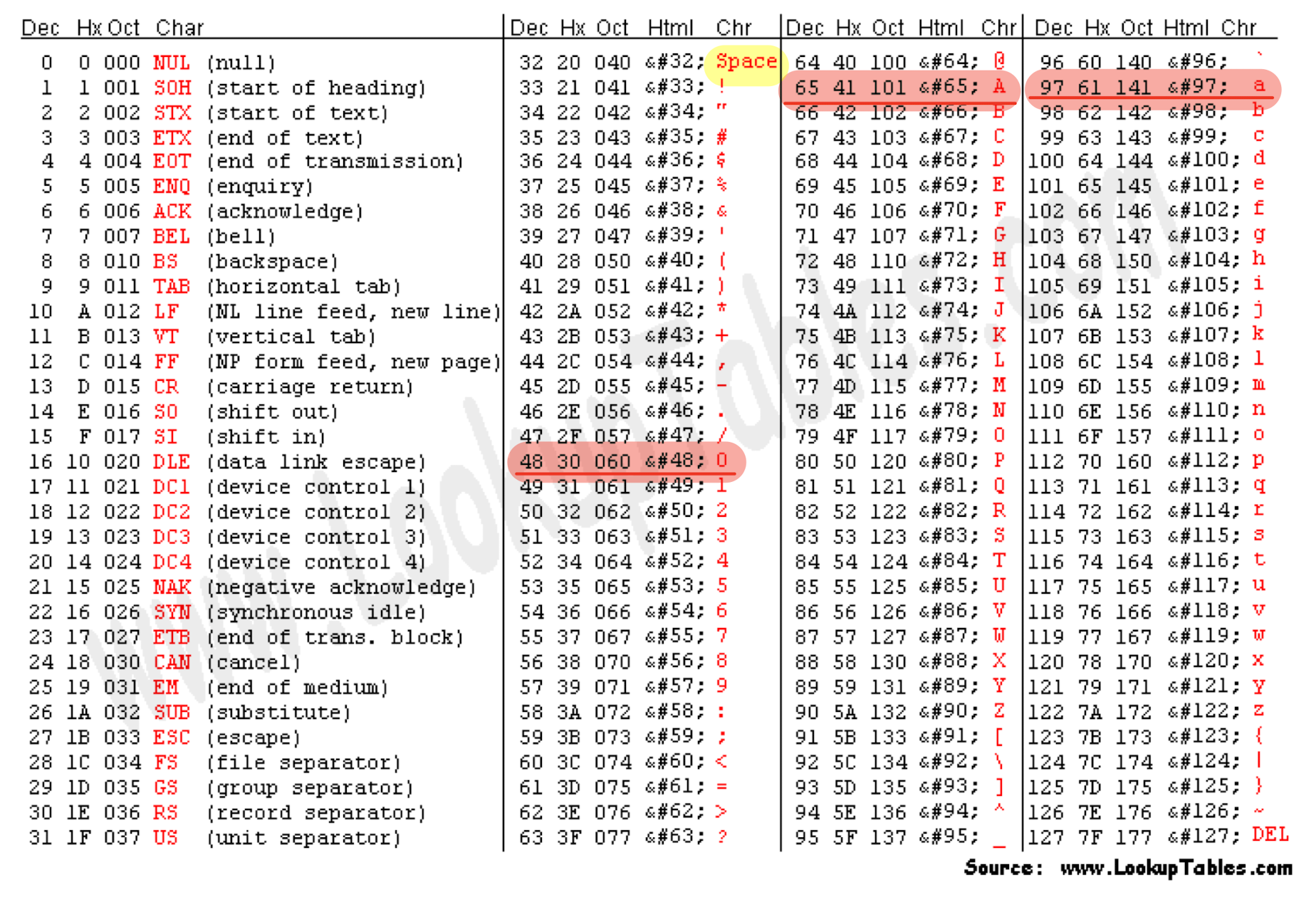
| ord()
ord("A") = 65
chr()
chr(65) = 'A'
|
3. List(列表)
- 和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
- 列表截取的语法格式如下:
变量[头下标:尾下标]
1
2
3
4
5
6
7
8
9
10
11
12
13
| list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]; tinylist = [123, 'runoob']
print (list)
print (list[0])
print (list[1:3])
print (list[2:])
print (tinylist * 2)
print (list + tinylist)
a = [1, 2, 3, 4, 5, 6]
a[0] = 9; a[2:5] = [13, 14, 15]
print(a)
a[2:5] = []
print(a)
|
| 方法 |
描述 |
| list.append(x) |
把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) |
通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) |
在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) |
删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) |
从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() |
移除列表中的所有项,等于del a[:]。 |
| list.index(x) |
返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) |
返回 x 在列表中出现的次数。 |
| list.sort() |
对列表中的元素进行排序。 |
| list.reverse() |
倒排列表中的元素。 |
| list.copy() |
返回列表的浅复制,等于a[:]。 |
4. Tuple(元组)
- 元组(tuple)与列表类似,不同之处在于 “元组的元素不能修改”。元组写在小括号 () 里,元素之间用逗号隔开。
- 元组中的元素类型也可以不相同:
1
2
3
4
5
6
7
8
9
10
11
12
| tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 )
tinytuple = (123, 'runoob')
print (tuple)
print (tuple[0])
print (tuple[1:3])
print (tuple[2:])
print (tinytuple * 2)
print (tuple + tinytuple)
tuple[0] = 11
tup1 = ()
tup2 = (20,)
|
| 方法及描述 |
实例 |
len(tuple)
计算元组元素个数。 |
tuple1 = ('Google', 'Runoob', 'Taobao')
len(tuple1) = 3 |
max(tuple)
返回元组中元素最大值。 |
>>> tuple2 = ('5', '4', '8')
max(tuple2) = '8' |
min(tuple)
返回元组中元素最小值。 |
>>> tuple2 = ('5', '4', '8')
min(tuple2) = '4' |
tuple(iterable)
将可迭代系列转换为元组。 |
>>> list1= ['Google', 'Taobao', 'Runoob', 'Baidu']
>>> tuple1 = tuple(list1)
tuple1 = ('Google', 'Taobao', 'Runoob', 'Baidu') |
5. Set(集合)
- 是一种无序、可变的数据类型, 集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
- 集合使用大括号 {} 表示,元素之间用逗号 “,” 分隔。
- 另外,也可以使用 set() 函数创建集合
1
2
3
4
5
6
7
8
9
| sites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}
print(sites)
a = set('abracadabra'); b = set('alacazam')
print(a)
print(a - b)
print(a | b)
print(a & b)
print(a ^ b)
|
6. Dictionary(字典)
- 列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
- 字典是一种映射类型,用 { } 标识,它是一个无序的 {键(key) : 值(value)} 的集合。键(key)必须使用不可变类型。
- 在同一个字典中,键(key)必须是唯一的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one'])
print (dict[2])
print (tinydict)
print (tinydict.keys())
print (tinydict.values())
del tinydict['name']
tinydict.clear()
del tinydict
dict()
dict(a='a',b='6',t='t')
dict(zip(['one', 'two', 'three'], [1, 2,3])
dict([('one', 1), ('two', 2), ('three', 3)])
for i in tinydict:
print(i, end = " ")
|
| 函数及描述 |
实例 |
len(dict)
计算字典元素个数,即键的总数。 |
>>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
len(tinydict) = 3 |
str(dict)
输出字典,可以打印的字符串表示。 |
>>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
str(tinydict) = "{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
type(variable)
返回输入的变量类型,如果变量是字典就返回字典类型。 |
>>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
type(tinydict) = <class 'dict'> |
Python字典包含了以下内置方法:
| 函数 |
描述 |
| dict.clear() |
删除字典内所有元素 |
| dict.copy() |
返回一个字典的浅复制 |
| dict.fromkeys() |
创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| dict.get(key, default=None) |
返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| key in dict |
如果键在字典dict里返回true,否则返回false |
| dict.items() |
以列表返回一个视图对象 |
| dict.keys() |
返回一个视图对象 |
| dict.setdefault(key, default=None) |
和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| dict.update(dict2) |
把字典dict2的键/值对更新到dict里 |
| dict.values() |
返回一个视图对象 |
| pop(key[,default]) |
删除字典 key(键)所对应的值,返回被删除的值 |
| popitem() |
返回并删除字典中的最后一对键和值 |
数据类型转换
1
2
3
4
5
6
| x = int(2.8)
y = float(1)
z = str(6.0)
a = x+y; print(a, type(a))
z = float(z); print(z, type(z))
|
if 语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
else age > 2:
human = 22 + (age -2)*5
print("对应人类年龄: ", human)
input("点击 enter 键退出")
|
循环语句
1
2
3
4
5
| var = 1
while var == 1 :
num = int(input("输入一个数字 :"))
print ("你输入的数字是: ", num)
print ("Good bye!")
|
1
2
3
4
5
6
| count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| for number in range(1, 6):
print(number, end = " ")
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
print(site, end = " ")
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
if site == "Runoob":
print("菜鸟教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
|


运算符
| 运算符 |
描述 |
示例 |
| / |
相除 |
a / b |
| % |
取模 |
a % b |
| ** |
幂 |
a**b 表示 a 的 b 次幂 |
| // |
取整除 |
9 // 4 结果为 2 |
| == |
是否相等 |
a == b |
| != |
是否不等于 |
a != b |
| >= |
是否大于等于 |
a >= b |
| += |
加法赋值运算符 |
a += b 等效于 a = a + b |
| **= |
幂赋值运算符 |
a = b 等效于 a = a**b |
参数传递
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,应该说传不可变对象和传可变对象。类型属于对象,对象有不同类型的区分,变量是没有类型的(可以通过 id() 函数来查看内存地址变化):
- 不可变数据 (immutable object):Number(数字)、String(字符串)、Tuple(元组)
- 可变数据 (mutable object):List(列表)、Dictionary(字典)、Set(集合)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| a=[1,2,3]
a="Runoob"
a = 5
print(id(a))
a = 10
print(id(a))
la=[1,2,3,4]
print(id(la))
la[2]=5
print(id(la))
|
传不可变对象实例:
1
2
3
4
5
6
7
8
9
10
11
| def change(a):
print(id(a))
a=10
print(id(a))
a=1
print(id(a))
change(a)
print(a)
print(id(a))
|
传可变对象实例:
1
2
3
4
5
6
7
8
9
10
11
|
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print (mylist)
return
mylist = [10,20,30]
changeme( mylist )
print (mylist)
|
lambda 匿名函数
虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,内联函数的目的是调用小函数时不占用栈内存从而减少函数调用的开销,提高代码的执行速度。
- lambda 只是一个表达式,而不是一个代码块,函数体比 def 简单很多。仅仅能在 lambda 表达式中封装有限的逻辑进去。
1
2
3
4
| def add(a, b=1):
return a+b
print(add(10, 20))
print(add(10))
|
翻译成 lambda 表达式就是:
1
2
3
| add_lambda = lambda a, b=1: a+b
print(add_lambda(10, 20))
print(add_lambda(10))
|
- 使用if条件文
1
2
3
| get_odd_even = lambda x:'even' if x%2==0 else 'odd'
print(get_odd_even(8))
print(get_odd_even(9))
|
- 无参数表达式
1
2
3
4
5
| import random
ran_lambda = lambda: random.random()
print(ran_lambda)
print(ran_lambda)
print(ran_lambda)
|
- map函数使用方法
使用map函数会对一个序列对象中的每一个元素应用被传入的函数,并且返回一个包含了所有函数调用结果的一个列表。
1
2
3
4
5
6
|
def add(x):
return x**2
a = map(add, [1,2,3,4])
print(list(a))
|
1
2
3
|
b = map(lambda x:x**2,[1,2,3,4,5])
print(list(b))
|
- filter和reduce函数使用方法
filter函数主要作用是基于某一测试函数过滤出一些元素
1
2
3
|
a=range(-5,5)
print(list(filter(lambda x:x>0,a)))
|
reduce 每一步传递当前的和或乘积以及列表中下一个的元素,传给列出的lambda函数。默认序列中的第一个元素初始化了起始值
1
2
3
4
5
6
| from functools import reduce
a=[1,2,3,4]
print(reduce(lambda x,y:x+y,a))
print(reduce(lambda x,y:x*y,a))
|
File Processing
Python open() 方法用于打开一个文件,并返回文件对象。
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
完整的语法格式为:
1
2
3
4
5
6
7
8
9
| open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
|
mode 参数有 (默认为文本模式,如果要以二进制模式打开,加上 b):
| mode |
描述 |
| t |
文本模式 (默认)。 |
| x |
写模式,新建一个文件,如果该文件已存在则会报错。 |
| b |
二进制模式。 |
| + |
打开一个文件进行更新(可读可写)。 |
| U |
通用换行模式(Python 3 不支持)。 |
| r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ |
打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w |
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb |
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ |
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ |
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 方法 |
描述 |
| file.close() |
关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() |
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() |
如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() |
Python 3 中的 File 对象不支持 next() 方法,返回文件下一行。 |
| file.read([size]) |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) |
读取整行,包括 “\n” 字符。 |
| file.readlines([sizeint]) |
读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) |
移动文件读取指针到指定位置 |
| file.tell() |
返回文件当前位置。 |
| file.truncate([size]) |
从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| file.write(str) |
将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) |
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |